本文是一篇利用对坑生成网络(GANs)进行图像去雨的paper Image Deraining Using a Conditional Generative Adversarial Network的笔记
介绍
雨天图像含有大量雨水,这对图像质量影响很大.传统图像去雨的思路是将图像$x$拆分成不含雨滴的高频分量$y$和雨滴构成的低频分量$w$:
$x=y+w$
由此产生的带有不同先验的各种方法都是在想办法进行合理拆分
这篇paper的思路是利用最近大行其道的神经网络对坑生成网络GANs进行$y$的生成
核心
用GAN的原因
GAN大行其道而且在图像处理领域非常成功
神经网络的结构
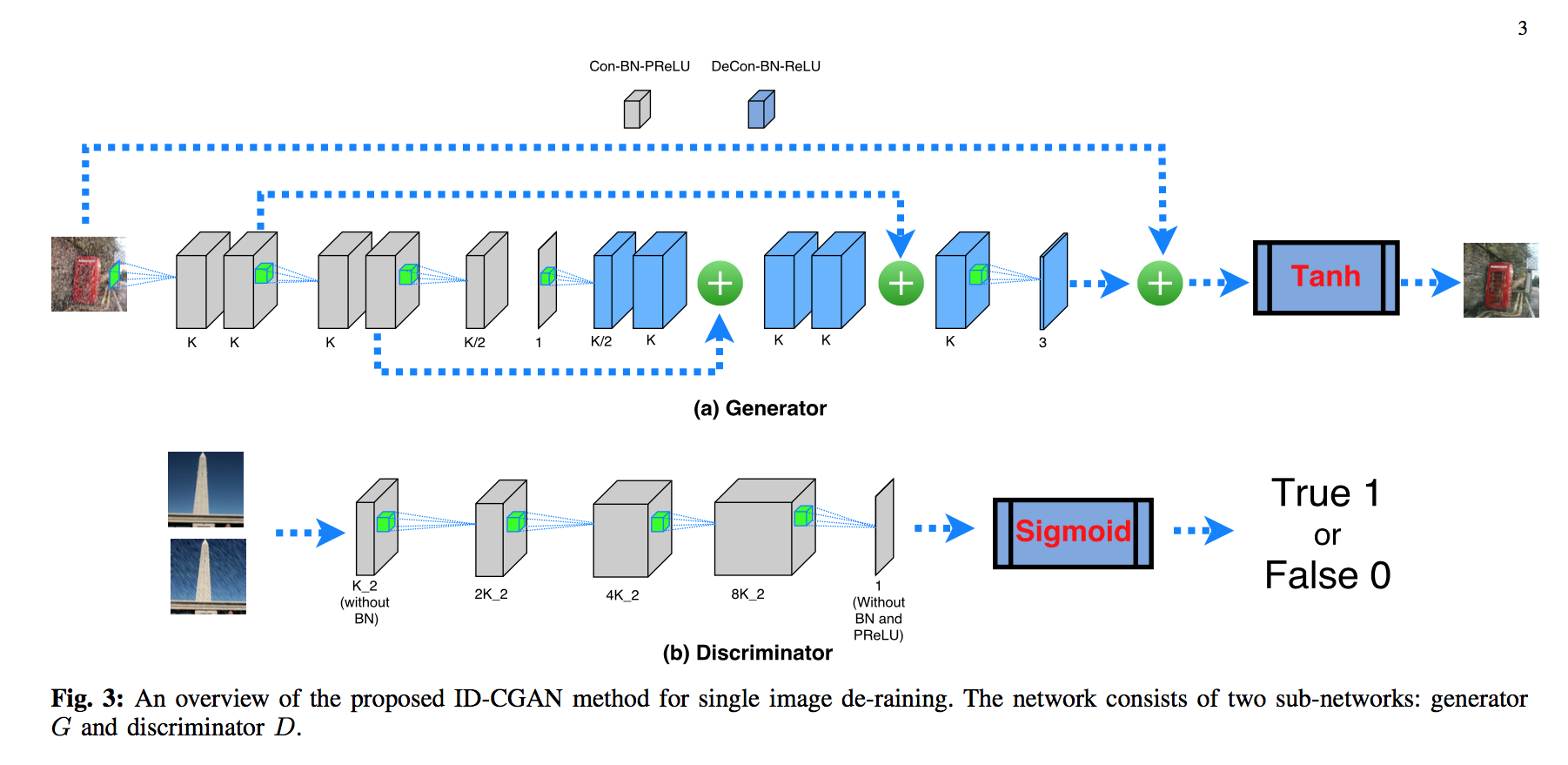
- 整体结构:
这个神经网络是经典的GAN,它由生成器(Generator)和判别器(Discriminator)组成;生成器给定原始图像生成去雨之后的图像,而判别器用来判别生成的图像和原始图像是否相像,G和D进行零和博弈,网络的权重在这个过程中被训练 - 判别器
判别器给定原始图像,然后经过了一个4+1+4+1的对称的ResNet(所谓”对称”就是有一个Conv层就会在后面有一个相应的DeConv层保持shape不变)最后和原始图像相加并进行Tanh处理就可以得到去雨图像,Generator的目标是尽可能生成真实的去雨图像:这个一方面是去雨程度,另一方面是和原图像在细节上面没有差别 - 生成器
生成器将生成的去雨图片和真实的去雨图片作为输入,经过5层Conv层和Sigmoid层之后输出True或False的判断Discriminator的目标是判断出生成的图片和真实的去雨图片相比是不是人工生成的
损失函数
这里的Loss Function借鉴了Li FeiFei Team在ECCV2016上面提出的perceptual loss的概念,最终的形式见下

- $L_E$是生成图像和真实去雨图像的L2损失
- $L_A$是对抗损失:这里的对抗损失,即与生成器一起训练一个判别器,其中判别模块的目的是为了区分开产生数据与真实数据;而生成器的目的则是为了尽量的迷惑判别器,其数学形式与原始GAN损失相似
- $L_P$是perceptual loss,即特征空间损失:它指生成图片和真实图片在一个新的比较器网络(这里选的是VGG16)里面的某一层的两者的特征图(feature map)的差异性
作者做了什么
- 提出了ID-CGAN的模型
- 比较了$λ_α$和$λ_p$在退化情况下模型的效果
- 比较了ID_CGAN和传统物理/计算机去雨方法的效果
总结
这篇paper的思路是利用原始图像作为输入,经过GANs输出一个处理后的图像.和传统GANs的不同之处在于将噪声分布替换为图像,网络的好处在于:
- 解答了困惑我很长时间关于GANs如何实现img2img的问题,这提示我后面做DhGANs的时候可以借鉴这种网络的结构,而且我预想直接copy也许都没有问题
- 这种网络没有涉及明显的物理模型/方法,和传统基于物理/计算机先验的方法相比,GANs可以自己学习img到img的映射方法,如果DhGANs可行的话可以通过它提取的特征或者损失函数来发现新的物理先验
- 训练好网络之后图像处理的速度非常高效
当然,ID-CGANs也存在缺点:
- 我们并不了解黑盒的机制,其中的物理无迹可寻
- 需要大量数据进行长时间的训练
- 生成的图片和原始图片可能存在细节不同,即人工生成的痕迹
- GANs本身的训练是不稳定的,迁移之后不能保证一定会收敛
后面可以将这个网络修改一下在使之能够作为DhNet运行